-
SQL 테스트 준비CS/Database 2022. 1. 2. 21:59반응형
JOIN
INNER JOIN
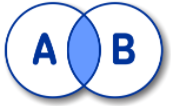
SELECT A.NAME FROM A INNER JOIN B ON A.ID = B.ID;LEFT OUTER JOIN

SELECT A.NAME FROM A LEFT OUTER JOIN B ON A.ID = B.ID;LEFT JOIN EXCLUDING INNER JOIN
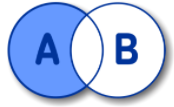
SELECT A.NAME FROM A LEFT OUTER JOIN B ON A.ID = B.ID WHERE B.ID IS NULL;RIGHT OUTER JOIN
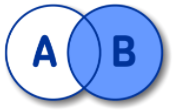
SELECT A.NAME FROM A RIGHT OUTER JOIN B ON A.ID = B.ID;RIGHT JOIN EXCLUDING INNER JOIN
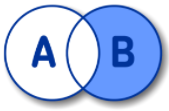
SELECT A.NAME FROM A RIGHT OUTER JOIN B ON A.ID = B.ID WHERE A.ID IS NULL;FULL OUTER JOIN
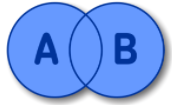
SELECT A.NAME FROM A FULL OUTER JOIN B ON A.ID = B.ID;FULL OUTER JOIN EXCLUDING INNER JOIN
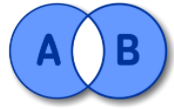
SELECT A.NAME FROM A FULL OUTER JOIN B ON A.ID = B.ID WHERE A.ID IS NULL OR B.ID IS NULL;문자열
LENGTH
length(n) → 문자열 n의 글자 수를 반환한다.
lengthb(n) → 문자열 n의 바이트 수를 반환한다.
select length(city) from station;SUBSTR
substr(str, pos, len) → char 문자열을 pos부터 len만큼 자른 문자열을 반환한다.
select substr(str,1,4), -- STR의 1번째 글자부터 4개 자르기 substr(str,5,5), -- STR의 5번째 글자부터 5개 자르기 substr(str,10), -- STR의 10번째 글자부터 끝까지 자르기 substr(str,-7,3), -- STR의 뒤에서 7번째 글자부터 3글자 자르기 substr(str,-3), -- STR의 뒤에서 3번째 글자부터 끝까지 자르기 from exampleINSTR
instr(str, target_str, pos, occur) → str에서 pos부터 occur번째 나타나는 target_str의 위치를 반환한다.
select -- str에서 ' '가 있는 위치 찾기 instr(str, ' '), -- str의 7번째 문자부터 ' '가 있는 위치 찾기 instr(str, ' ', 7), -- str의 7번째 문자부터 2번째 ' '가 있는 위치 찾기 instr(str, ' ', 7,2), -- str의 1번째 문자부터 2번째 ' '가 있는 위치까지 str 자르기 substr(str, 0, instr(str, ' ', 1, 2)) from exampleCONCAT
concat(str1, str2, str3, ...) → str1, str2, str3, ... 를 합친 문자열을 반환한다.
select concat(id, name, address) from person;REPLACE
replace(해당컬럼명,'해당문자','바꿀문자')
select replace(salary, 0, '') from employees; select replace(phone_number, '-', '') from employees;숫자
집계 함수 - SUM, AVG, MAX, MIN, COUNT
select sum(score) from student; select avg(score) from student; select max(score), min(score) from student; select count(*) from student;MOD
mod(m, n) → m을 n으로 나눴을 때 나머지를 반환한다.
select * from CITY where mod(ID, 2) = 1;ROND, FLOOR, CEIL
- round(값, 반올림 자릿수) → 반올림
- floor(값) → 내림
- ceil(값) → 올림
select round(avg(population)) from city; select floor(avg(population)) from city; select ceil(avg(population)) from city;-- 소수점 반올림 select round(1234.5) -- 1235 select round(1234.567, 2) -- 1234.56 -- 정수 반올림 select round(1234, -1) -- 1230 select round(1234, -2) -- 1200 select round(1234, -3) -- 1000 -- 날짜 반올림 SELECT ROUND(to_date('2019-08-12 11:50', 'yyyy-mm-dd hh24:mi')) -- 2019-08-12 00:00:00 SELECT ROUND(to_date('2019-08-12 12:10', 'yyyy-mm-dd hh24:mi')) -- 2019-08-13 00:00:00SQRT, POWER
- sqrt(대상 숫자)
- power(대상 숫자, 거듭제곱 횟수)
select sqrt(4); // 2 select power(2, 2) // 4순위
ROW_NUMBER
중복 값들에 대해서도 순차적인 순위를 표시하도록 출력하는 함수
- row_number() over ([partition by 절] order by 절)
SELECT row_number() OVER (ORDER BY salary DESC) 번호 FROM employee;RANK
순위를 매기는 함수, 중복 값들에 대해서 동일 순위로 표시하고, 중복 순위 다음 값에 대해서는 중복 개수만큼 떨어진 순위로 출력하도록 하는 함수
- rank() over ([partition by 절] order by 절)
SELECT RANK() OVER (ORDER BY salary DESC) 등수 FROM employee;DENSE_RANK
순위를 매기는 함수, 중복 값들에 대해서 동일 순위로 표시하고, 중복 순위 다음 값에 대해서는 중복 값 개수와 상관없이 순차적인 순위 값을 출력하도록 하는 함수
- dense_rank() over ([partition by 절] order by 절)
SELECT DENSE_RANK() OVER (ORDER BY salary DESC) 등수 FROM employee;PERCENT_RANK
특정값(수치)이 전체에서 몇퍼센트인지를 계산하여 알려주는 함수
- percent_rank() over ([partition by 절] order by 절)
SELECT PERCENT_RANK() OVER (ORDER BY salary DESC) 퍼센트 FROM employee;NTILE
파라미터 값만큼으로 등분을 하는 함수
- ntile(숫자) over ([partition by 절] order by 절)
SELECT NTILE(4) OVER (ORDER BY salary DESC) 등수 FROM employee;PARTITION BY
그룹 내 순위 및 그룹 별 집계를 구할 때 유용하게 사용할 수 있다.
SELECT 순위함수() OVER (PARTITION BY 컬럼명 ORDER BY 컬럼명) FROM 테이블명 SELECT 집계함수(컬럼명) OVER (PARTITION BY 컬럼명) FROM 테이블명조건
IF
if(조건, true일 때 값, false일 때 값)
SELECT IF (NAME is null, "No name", NAME) AS NAME FROM ANIMAL_INS;IFNULL
ifnull(컬럼, null일 때 값)
SELECT IFNULL(NAME, 'No name') AS NAME FROM ANIMAL_INS;CASE
조건문에 따라 값을 지정해주기 위해 사용
select (case when count > 0 then 'O' else 'X' end) from example;LIKE
- 특정 문자열로 시작하는 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE 'A%';- 특정 문자열로 끝나는 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '%A';- 특정 문자열을 포함하는 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '%A%';- 특정 문자열로 시작하는 두 글자 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE 'A_';- 특정 문자열로 끝나는 두 글자 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '_A';- 첫번째 문자가 'A'가 아닌 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '[^A]';- 첫번째 문자가 'A','B','C'인 문자열 찾기
SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '[ABC]'; SELECT NAME FROM ANIMAL_INS WHERE NAME LIKE '[A-C]';정규식
REGEXP
매칭
패턴 기능 사용 예시 설명 . 문자 하나 '...' 문자열의 길이가 세 글자 이상인 문자열을 찾음 | 또는(OR), |로 구분된 문자에 해당하는 문자열을 찾음 'a|b' 'a' 또는 'b'에 해당하는 문자열을 찾음 [] []안에 나열된 패턴에 해당하는 문자열을 찾음 '[123]d' 대상 문자열에서 '1d' 또는 '2d' 또는 '3d'인 문자열을 찾음 ^ 시작하는 문자열을 찾음 '^a' 대상 문자열에서 'a'으로 시작하는 문자열을 찾음 $ 끝나는 문자열을 찾음 'b$' 대상 문자열에서 'b'로 끝나는 문자열을 찾음 수의 제한
패턴 기능 사용 예시 설명 * 0회 이상 나타나는 문자 'a*' 'a'가 0번 이상 나타나는 문자열을 찾음 + 1회 이상 나타나는 문자 'a+' 'a'가 1번 이상 나타나는 문자열을 찾음 {m,n} m회 이상 n회 이하 나타나는 문자 'a{1,2}' 'a'가 1회 이상 2회 이하 나타나는 문자열을 찾음 ? 0-1회 나타나는 문자 'a?' a가 0-1회 나타나는 문자열을 찾음 문자 그룹
패턴 기능 사용 예시 설명 [A-z] 또는 [:alpha:] 또는 \a 알파벳 대문자 또는 소문자인 문자열을 찾음 '[A-z]+' 대상 문자열에서 알파벳이 한 개 이상인 문자열을 찾음 [0-9] 또는 [:digit:] 또는 \d 숫자인 문자열을 찾음 '^[0-9]+' 한 개 이상의 숫자로 시작하는 문자열을 찾음 부정
패턴 기능 사용 예시 설명 [^문자] 괄호 안의 문자를 포함하지 않은 문자열을 찾음 '[^abc]' ‘a’ 또는 ‘b’ 또는 ‘c’를 포함하지 않는 문자열을 찾음 select city from station where city not regexp '[aeiou]$';DATETIME
DATE_FORMAT
date_format(날짜, 형식): 날짜를 지정한 형식으로 출력
구분 기호 역할 구분 기호 역할 %Y 4자리 년도 %m 월(두자리 수) %y 2자리 년도 %c 월(한자리일 경우 한자리 수) %M 월(긴 영문) %d 일(두자리 수) %b 월(짧은 영문) %e 일(한자리일 경우 한자리 수) %W 요일(긴 영문) %h / %I 시간(12시간) %a 요일(짧은 영문) %H 시간(24시간) %r hh:mm:ss AM, PM %i 분 %T hh:mm:ss %s / %S 초 select curdate() -- 2022-01-12 00:00:00 select curtime() -- 02:33:45 select now() -- 2022-01-12 02:33:45 select sysdate() -- 2022-01-12 02:33:45 -- 년도 select year(curdate()) -- 2022 select date_format(now(), '%Y') -- 2022 select date_format(now(), '%y') -- 22 -- 월 select month(curdate()) -- 1 select date_format(now(), '%M') -- January select date_format(now(), '%b') -- Jan select date_format(now(), '%m') -- 01 select date_format(now(), '%c') -- 1 -- 일 select day(curdate()) -- 12 select date_format('2022-01-01', '%d') -- 01 select date_format('2022-01-01', '%c') -- 1 -- 요일 (1(일), 2(월), 3(화), 4(수), 5(목), 6(금), 7(토)) select dayofweek(curdate()) -- 4 (수) select date_format(now(), '%W') -- Wednesday select date_format(now(), '%a') -- Wed -- 시간 select hour('23:02:11') -- 23 (시간) select date_format('2022-01-01 23:00:00', '%H') -- 23 (시간) select date_format('2022-01-01 23:00:00', '%h') -- 11 (시간) select date_format('2022-01-01 23:00:00', '%I') -- 11 (시간) -- 분 select minute('23:02:11') -- 2 (분) select date_format('2022-01-01 23:12:00', '%i') -- 12 (분) -- 초 select second('23:02:11') -- 11 (초) select date_format('2022-01-01 23:12:59', '%s') -- 59 (초) select date_format('2022-01-01 23:12:59', '%S') -- 59 (초) -- 시:분:초 (AM/PM) select date_format('2022-01-01 23:12:59', '%r') -- 11:12:59 PM select date_format('2022-01-01 11:12:59', '%r') -- 11:12:59 AM select date_format('2022-01-01 23:12:59', '%T') -- 23:12:59 select date_format('2022-01-01 11:12:59', '%T') -- 11:12:59변수
SET @변수이름 = 변수의 값
set @time=-1; select @time:=@time+1 AS HOUR, (select count(datetime) from ANIMAL_OUTS where @time=hour(datetime)) AS COUNT from ANIMAL_OUTS where @time < 23 order by @time반응형'CS > Database' 카테고리의 다른 글
[Database] Database Scan (0) 2022.01.19 [Database] Transaction과 Isolation Levels (0) 2022.01.19 [Database] Clustered Index와 Non-clustered Index (0) 2022.01.17 [Database] Index (0) 2022.01.14