-
[Database] Database ScanCS/Database 2022. 1. 19. 21:18반응형
Database Scan
앞선 인덱스 포스팅에서 항상 테이블 풀 스캔이 느린 것만은 아니라고 말했다. 어떤 경우에는 인덱스 스캔보다 테이블 풀 스캔이 빠른 경우도 있다. 데이터베이스의 데이터를 스캔하는 방법에는 여러가지 종류가 있고, 어떤 방법이 가장 최적의 방법이라고 말할 수 없다. 다양한 방법 중 적합한 방법을 적용하여 데이터베이스 성능을 높이는 것이 중요하다.
다양한 스캔 방법에 대해 알아보자.
Table Full Scan
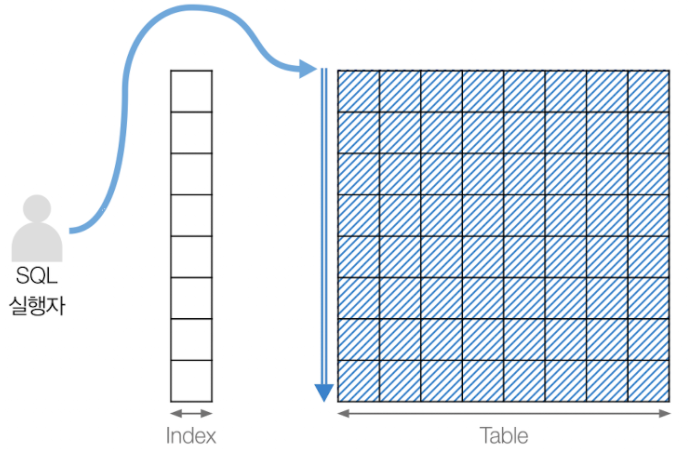
출처: https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC - 인덱스를 거치지 않고 테이블에 있는 모든 레코드를 읽는 방법
- 다중 블록 단위로 메모리에 옮겨지며, 이 블록들은 순차적으로 읽혀진다.
(Sequential access + Multi Block I/O) - 일반적으로 블록들은 서로 인접해 있기 때문에 한 번의 I/O로 처리 가능하다.
- 한 번에 액세스하는 블록의 양을 정의하기 위해 DB_FILE_MULTIBLOCK_READ_COUNT를 지정한다.
Optimizer가 Table Full Scan을 선택하는 경우
- 적용 가능한 인덱스가 없을 때
- 넓은 범위의 데이터 액세스
- 적용 가능한 인덱스가 존재하더라도 처리 범위가 넓어 테이블 풀 스캔이 더 적은 비용이 든다면 테이블 풀 스캔을 적용할 수 있음
- 병렬처리 액세스
- 병렬처리는 테이블 풀 스캔을 더욱 효과적으로 수행하기 때문에 병렬처리로 수행되는 실행 계획을 수립할 때는 항상 테이블 풀 스캔을 선택함
- 'FULL' 힌트를 적용했을 때
- FULL 힌트가 적절하지 않다면 옵티마이저가 이를 무시할 수 있음
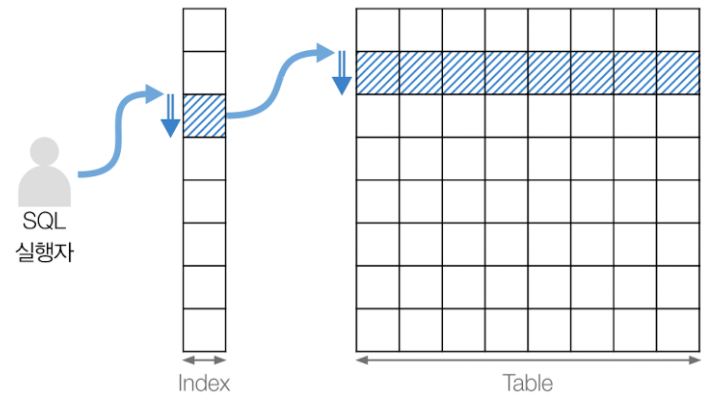
Index Range Scan
출처: https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC - 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있어야 가능
- 인덱스에서 일정량을 스캔하면서 얻은 ROWID로 테이블 레코드를 찾음
- 단일 블록 단위로 메모리에 옮겨지며, 이 블록들은 랜덤하게 읽혀진다.
(Random access + Single Block I/O) - Sequential access + Multi Block I/O가 좋아도 소량의 데이터를 찾을 때 테이블 전체를 스캔하는 것은 비효율적이기 때문에 대용량 테이블에서 소량의 데이터를 찾을 때는 반드시 인덱스를 사용해야 함
- 반대로 대량의 데이터를 찾을 때는 레코드 별로 매번 I/O call이 필요하기 때문에 테이블 풀 스캔보다 불리함
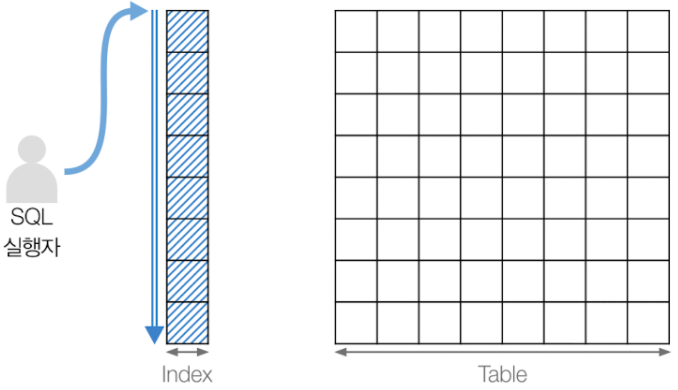
Index Unique Scan
출처: https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC - 단 하나의 ROWID를 추출해 레코드를 찾는 방법
- 인덱스가 PK나 Unique index로 생성되어 있어야 하며, 인덱스를 구성하는 모든 컬럼들이 모두 조건절에서 '=' 비교되어야 함
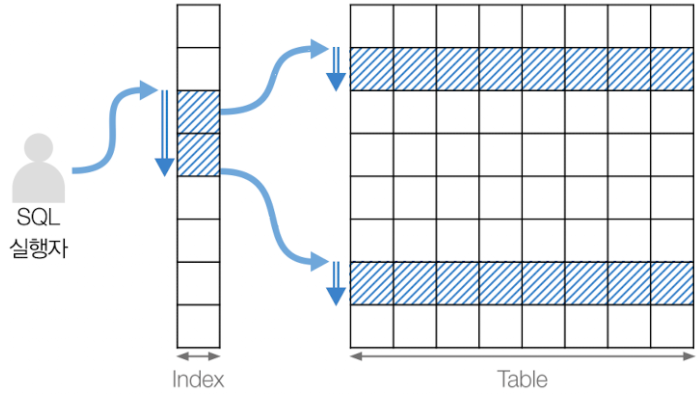
Index Loose Scan

출처: https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC - 인덱스에서 필요한 부분만 선택하여 스캔하는 방법
- 인덱스 레인지 스캔과 비슷하게 동작하지만 중간마다 필요하지 않은 키 값은 무시함
- 일반적으로 group by 또는 min, max 등의 함수에 대해 최적화할 때 사용
select dept_no, min(emp_no) from dept_emp where dept_no between 'd002' and 'd004' group by dept_no;dept_emp 테이블은 (dept_no, emp_no) 컬럼으로 다중 컬럼 인덱스를 구성하고 있다고 가정하며, 이 인덱스는 (dept_no, emp_no)를 기준으로 정렬이 되어 있다. 즉 특정 dept_no 그룹 별로 처음에 있는 emp_no만 읽으면 된다. 즉, 인덱스에서 where 조건을 만족하는 범위 전체를 다 스캔할 필요가 없다는 것을 옵티마이저는 알고 있으므로 중간 중간 조건에 맞지 않으면 건너 뛴다.

출처: https://steady-coding.tistory.com/546 Index Full Scan
출처: https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC - 인덱스 선두 컬럼이 조건절에 없으면, 인덱스 레인지 스캔이 불가능하기 때문에 옵티마이저는 테이블 풀 스캔을 고려함
- 하지만 대용량 테이블이라 테이블 풀 스캔에 대한 부담이 크면 인덱스를 활용할 필요가 있음
- 인덱스의 전체 크기는 테이블의 전체 크기보다 훨씬 적기 때문에 인덱스 레인지 스캔을 할 수 없을 때, 테이블 풀 스캔보다는 인덱스 풀 스캔이 더 좋을 수 있음
- 인덱스 풀 스캔을 통해 대부분의 레코드를 필터링하고 일부만 테이블 액세스하는 상황이라면 인덱스 풀 스캔이 유리함
select * from emp where salary > 9000 order by emp_no;emp 테이블은 (emp_no, salary) 컬럼으로 다중 컬럼 인덱스를 구성하고 있다고 가정하면, 조건절 선두에 인덱스 선두 컬럼인 emp_no가 없어서 인덱스 레인지 스캔이 불가능하다. salary > 9000인 레코드가 전체 테이블에서 아주 작은 일부라면 테이블 풀 스캔보다 인덱스 풀 스캔이 유리할 수 있다.
하지만 인덱스 풀 스캔은 인덱스 레인지 스캔을 하지 못한 차선책이기 때문에 salary 컬럼이 선두 컬렁니 인덱스를 생성하는 것이 좋다.
Reference
https://velog.io/@jooh95/DB-Scan-%EC%A2%85%EB%A5%98-%EC%A0%95%EB%A6%AC
https://steady-coding.tistory.com/546
http://wiki.gurubee.net/pages/viewpage.action?pageId=12517471
반응형'CS > Database' 카테고리의 다른 글
[Database] Transaction과 Isolation Levels (0) 2022.01.19 [Database] Clustered Index와 Non-clustered Index (0) 2022.01.17 [Database] Index (0) 2022.01.14 SQL 테스트 준비 (0) 2022.01.02